
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- STP
- Cisco
- SQL
- 방화벽
- LACP
- Red Hat
- 네트워크 설계
- ansible playbook
- junos os
- 네이티브 vlan
- BPDU
- pagp
- freeradius
- rommon mode
- Packet Tracer
- vlan
- stream 9
- 하프오픈
- eigrp
- 오블완
- Network Design
- 네트워크
- gns3
- 티스토리챌린지
- 프로그래머스
- port aggregation protocol
- centos
- Ansible
- pvst+
- ospf
- Today
- Total
Doctor Pepper
[물리 계층과 데이터 링크 계층] LFP(Link Fault Propagation) 본문
1. LLCF/LLR
LLCF(Link Loss Carry Forward)와 LLR(Link Loss Return) 기술은 회선 장애나 물리적인 포트 장애로 인한 패킷 손실을 최소화하고, 회선의 관리와 장애 처리 효율성을 높이는 데 사용되는 기술이다. 이러한 기술은 UTP 케이블을 광케이블로 변환하는 미디어 컨버터나, SONET을 기반으로 한 전송을 처리하는 MSPP(Multi-Service Provisioning Platform)와 같은 전송 장비에서 사용된다. Cisco에서는 이를 ‘종단 간 이더넷 링크 무결성(End-to-End Ethernet Link Integrity)’ 기능이라고 부른다.

- 기능
이 기술은 통신 경로에서 발생한 특정 구간의 장애가 전체 통신 경로의 장애로 간주되어, 장애 발생 시 해당 경로의 상태를 즉시 알리고, 장애 구간의 라우팅을 갱신하여 서비스의 연속성을 확보할 수 있게 한다. 예를 들어, MSPP 간의 SONET 전송 구간이나 연결된 이더넷 구간에 장애가 발생하면, 이를 감지한 장비는 상대 MSPP에 에러 시그널인 CSF(Client Signal Fail)를 전달하여 원격지 포트를 비활성화시키고, 장애를 알리는 알람을 발생시킨다. 이렇게 장애를 즉시 처리함으로써, 통신 시스템이 장애를 감지하고 이를 반영하여 서비스를 지속적으로 제공할 수 있다.
- 동작 방식
| MSPP 간의 장애 감지 | SONET 전송 구간에 장애가 발생하면, 원격지 이더넷 포트가 시그널을 수신하지 못하거나 SONET 전송로의 장애를 감지한 장비는 이를 상대방 장비에 알려주고, 해당 포트를 비활성화시킨다. |
| 미디어 컨버터의 동작 | UTP 포트에 장애가 발생하면, 광케이블로 변환하는 미디어 컨버터가 광 포트로의 시그널 전송을 중단하여 원격지의 광 링크를 비활성화시킨다. |
| 보안 장비의 역할 | 대부분의 보안 장비, 특히 침입 탐지 시스템(IDS), 침입 차단 시스템(IPS), 방화벽(FW)은 LLCF 기능을 지원하여, 장애 발생 시 패킷 흐름을 중단하고 자동으로 장애 구간을 우회하도록 한다. |
예를 들어, SW1과 SW2, SW3가 IPS를 통해 구성되고, SW3는 Static 라우팅을 사용해 로드 밸런싱 구조로 서비스를 제공하는 상황에서, IPS1과 SW1 간 연결 링크에 장애가 발생하면, SW3는 원경 링크의 다운을 감지하지 못하고 계속해서 ISP1로 패킷을 전송하게 된다. 이 상황에서 LLCF 기능이 지원되는 IPS 장비는 장애를 감지하고, SW3와 연결된 인터페이스를 강제로 다운시켜 장애가 발생한 구간의 라우팅 정보를 갱신하도록 한다. 이를 통해 서비스의 연속성을 보장하고, 이중화된 경로로 패킷을 우회시켜 정상적인 통신을 유지할 수 있다.

2. LLCF 동작
LLCF는 물리적인 인터페이스에서 링크 시그널을 수신하지 못하면 해당 인터페이스에서 송신하는 링크 시그널을 전송하지 않는 기능이다. 이 기능은 광(Optical) 포트나 TP(Twisted Pair) 포트에 설정되어, 원격지의 링크 장애를 네트워크 장비가 인지할 수 있도록 한다. 이를 통해 라우팅 테이블, ARP 테이블, MAC 테이블 등을 재수렴(연산)하여 장애 발생 구간을 신속하게 반영할 수 있다.

- 동작 과정
| 링크 장애 감지 | - 네트워크 장비에서 링크 다운이 발생하면, LLCF 기능이 활성화된 라인 카드는 해당 장애 정보를 NMS(네트워크 관리 시스템)와 같은 관리 시스템으로 트랩(trap)을 발생시킴. |
| 링크 시그널 전송 중단 | - 링크가 다운된 상태에서, 장비는 원격지에서 링크 시그널을 수신할 때까지 반대편 포트로 시그널을 전송하지 않음. - 이를 통해 네트워크 장애가 감지되며, 관리자에게 장애 발생 구간에 대한 정보를 전달할 수 있음. |
| 라우팅 테이블 갱신 | - 네트워크 장비는 링크 장애를 감지하면, 해당 정보를 바탕으로 라우팅 테이블, ARP 테이블, MAC 테이블 등을 재수렴하여 장애 구간을 우회하도록 처리함. |
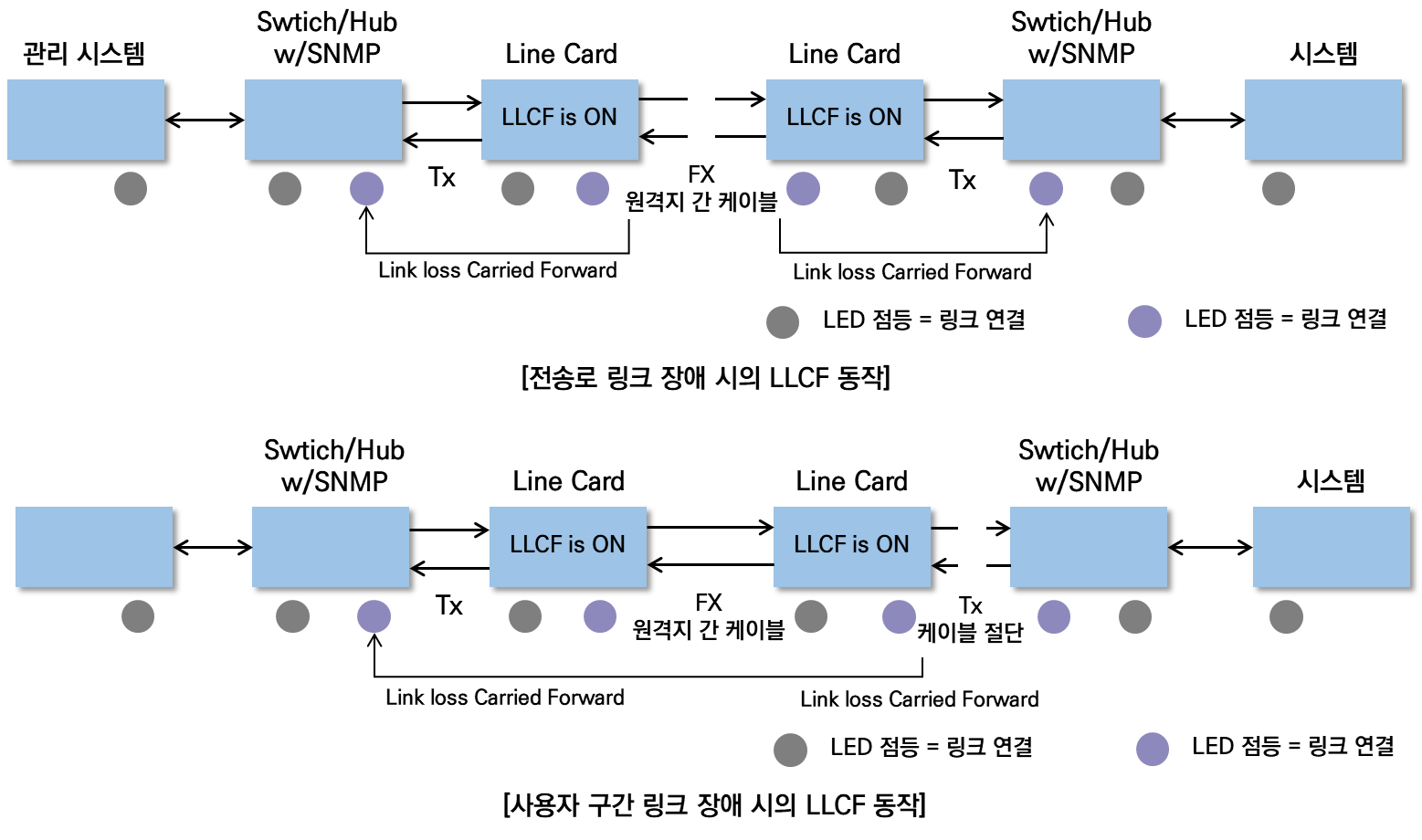
- LLCF와 자동 협상(AN) 기능
자동 협상 기능이 활성화된 장비에서 LLCF를 설정할 때는, 가능한 경우 자동 협상 기능을 비활성화하고, 로컬과 원격지 간의 속도 및 듀플렉스를 강제로 설정하는 것이 좋다. 이렇게 하면 라인 카드가 링크 펄스를 즉시 감지할 수 있다. 하지만 LLCF가 설정된 장비와 이더넷 라우터, 스위치 간에는 자동 협상 기능을 활성화해야 한다.
- LLCF와 연계 장비의 동작
LLCF가 활성화된 장비는 로컬 이더넷 구간에서 장애를 탐지하면, 이를 원격지 LLCF 장비에 전달하여 원격지 장비가 자신과 연결된 이더넷 인터페이스를 비활성화하도록 유도한다. 이때, 연계 장비의 인터페이스를 비활성화하는 데 자동 협상 기능에서 사용하는 링크 무결성과 관련된 코드 워드 정보가 사용된다. 이렇게 함으로써 연계된 이더넷 장비가 장애가 발생한 구간을 인식하고, 해당 인터페이스를 비활성화시켜 장애를 관리할 수 있다.
3. LLR 동작
LLR(Link Loss Return) 기능은 LLCF(Link Loss Carry Forward)와 함께 동작하는 기술로, 네트워크의 링크 상태를 관리하는 데 중요한 역할을 한다. LLR 기능은 인터페이스의 수신부(RX)가 유효한 신호를 감지하지 못하면, 해당 인터페이스의 전송부(TX)를 강제로 비활성화시키는 기술이다. 이를 통해 링크 장애가 발생했을 때, 장애 구간을 신속하게 인지하고 처리가 가능하다.
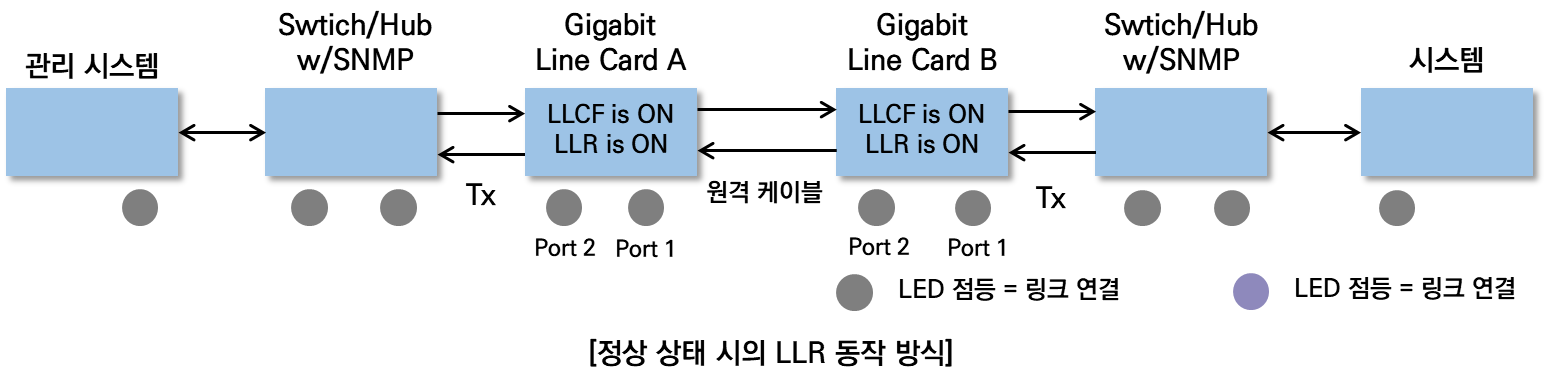
- 동작 과정
| 링크 장애 감지 | - 광 접속 단자에 장애가 발생하면, 링크 장애를 감지한 라인 카드(B)는 상대 링크 파트너에게 링크 훼손에 대한 에러 정보를 전송함. |
| LLR 및 LLCF 동작 | - 장애를 감지한 라인 카드 B는 LLCF 기능을 활성화하여, 로컬 인터페이스를 다운 상태로 유도함. - 이는 로컬 장비가 장애를 인식하고, 이후의 처리를 위한 준비를 하도록 도움. |
| 상대방 라인 카드 반응 | - 이를 인지한 라인 카드 A는 동일하게 LLCF 기능을 활성화시켜, 장애 포트에 대응하는 자신의 로컬 인터페이스를 다운 상태로 설정함. - 이를 통해 양쪽 장비 모두 장애를 인식하고, 해당 구간의 서비스에 영향을 미치지 않도록 함. |
- LLR 동작의 특징
| 광 라인 카드에서 동작 | LLR 기능은 주로 광 라인 카드에서 동작하며, 광 접속 단자와 관련된 링크 장애를 처리함. |
| LLC와 연계 | LLR은 LLCF 기능과 함께 사용되어, 장애 발생 시 두 기능이 상호 연동하여 장애를 효율적으로 관리하고 서비스 연속성을 유지함. |
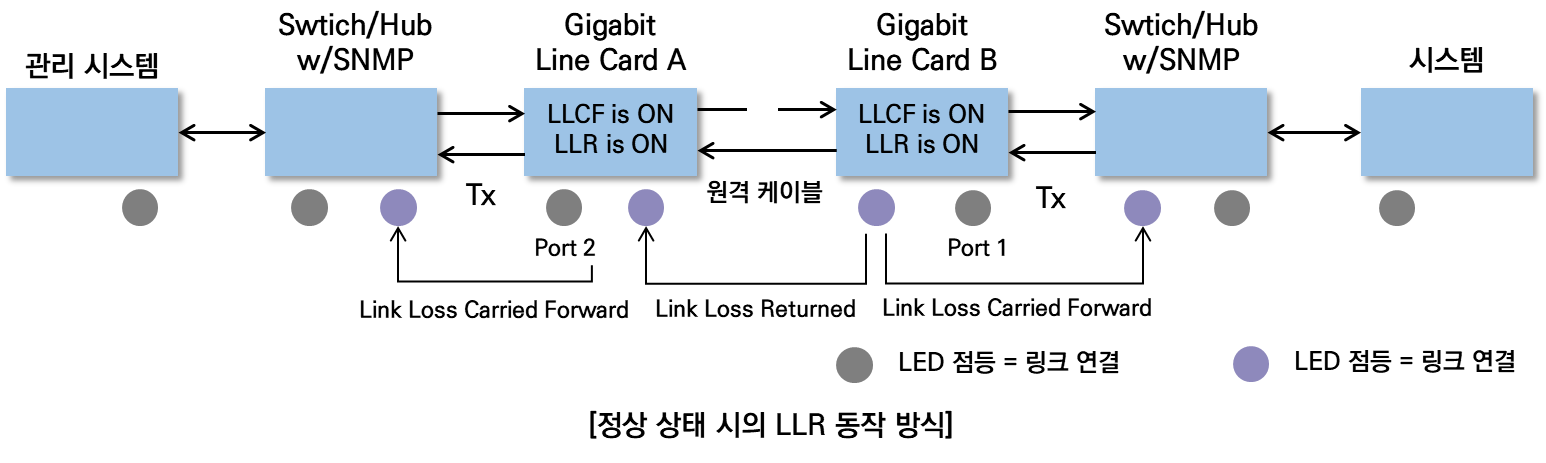
4.LLCF 기능이 지원되지 않는 경우 네트워크 구성 방안
- LLCF 미지원 환경의 문제점
LLCF가 지원되지 않는 장비를 사용하는 경우, 특정 회선 장애가 발생하면 이를 상위 레이어로 전달하지 못하여 서비스 장애가 발생할 수 있다. 특히, 정적 라우팅 환경에서 장애 회선이 계속 라우팅 테이블에 남아 있는 경우 패킷 전달이 실패할 수 있다.
- 대안적 장애 복구 방법
| Cisco 트래킹 기능 활용 | - Cisco의 트래킹 기능은 네트워크 연결성을 모니터링하고 장애 발생 시 경로를 동적으로 전환하는 데 사용됨. · 필수 조건 : Cisco 라우터 장비 및 IOS Enterprise Version 12.3(4)T 이상. · 지원 프로토콜 : ICMP/UDP Ping, HTTP Get Request. |
| ARP 캐시 갱신 주기 단축 | - 기본적으로 ARP 캐시 갱신 주기가 4시간으로 설정된 Cisco 장비의 특성을 극복하기 위해 갱신 주기를 1초로 줄이는 방안을 고려할 수 있음. - 이 방법은 장애 감지 및 복구 시간을 최소화함. |
- 정적 라우팅 구성
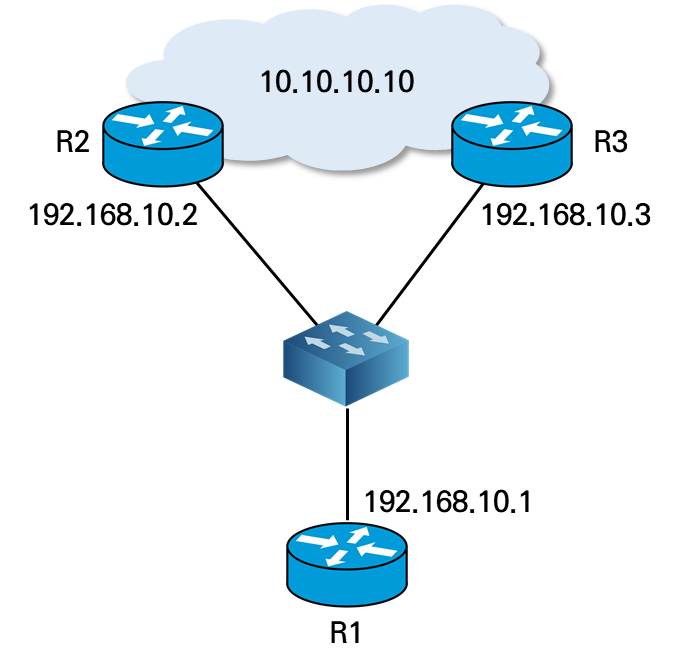
ISP와 연결된 네트워크에서 메트로 이더넷 스위치를 사용하여 정적 라우팅을 구성할 수 있다. ISP 장비는 R2, R3이며, 사용자 측 장비는 R1이다.
| R1 # show run version 12.4 ! no ip cef # 프로세스 스위칭으로 로드 셰어링의 테스트를 위해 ip cef 기능을 비활성화함 no ip domain lookup ! ip sla monitor 1 type echo protocol ipIcmpEcho 192.168.10.2 timeout 500 # 타임아웃 시간을 500으로 조정함 frequency 1 # ICMP 체크 시간을 1초마다로 조정함 ip sla monitor schedule 1 life forever start-time now ip sla monitor 2 type echo protocol ipIcmEcho 192.168.10.3 timeout 500 # 타임아웃 시간을 500으로 조정함 frequency 1 # ICMP 체크 시간을 1초마다로 조정함 ip sla monitor schedule 2 life forever start-time now !! track 10 rtr 1 reachability # Response Time Reporter 10에 sla monitor 1 매칭 ! track 20 rtr 2 reachability # Response Time Reporter 20에 sla monitor 2 매칭 ! interface Loopback0 ip address 192.168.10.1 255.255.255.0 ! interface FastEthernet0/0 ip address 192.168.10.1 255.255.255.0 no ip route-cache # 테스트를 위해 인터페이스에 process switching 기능 활성화 duplex auto speed auto ip route 0.0.0.0 0.0.0.0 192.168.10.2 track 10 # tracking을 적용 icmp 체크 활성화 ip route 0.0.0.0 0.0.0.0 192.168.10.3 track 20 # tracking을 적용 icmp 체크 활성화 |
R1 라우터가 ISP 라우터 인터페이스로 ICMP 트래킹을 통해 회선의 생존성을 체크하는 방식에서 정상 동작 시 R1의 라우팅 테이블과 ARP 캐시 정보는 다음과 같다.
- R1 라우팅 테이블
| Gateway of last resort is 192.168.10.3 to network 0.0.0.0 C 192.168.10.0/24 is directly connected, FastEthernet0/0 C 192.168.100.0/24 is directly connected, Loopback0 S* 0.0.0.0/0 [1/0] via 192.168.10.3 [1/0] via 192.168.10.2 |
- R1 ARP 캐시 정보
| Protocol Address Age(min) Hardware Addr Type Interface Internet 192.168.10.2 1 cc01.0400.0000 ARPA FastEthernet0/0 Internet 192.168.10.3 81 cc02.0400.0000 ARPA FastEthernet0/0 Internet 192.168.10.1 - cc00.0400.0000 ARPA FastEthernet0/0 |
이 정보는 R1 라우터가 ISP와의 연결을 모니터링하면서 ICMP 트래킹을 통해 회선의 상태를 지속적으로 확인하는 정상적인 동작을 기반으로 한다.
R1에서 10.10.10.10으로 핑 테스트를 수행하고, R2의 Fa0/0 인터페이스를 비활성화한 후, 패킷이 R2와 R3를 통해 전달되던 상황에서 R1의 라우팅 테이블과 ARP 캐시 정보는 다음과 같다.
- R1 라우팅 테이블
| Gateway of last resort is 192.168.10.3 to network 0.0.0.0 C 192.168.10.0/24 is directly connected, FastEthernet0/0 C 192.168.100.0/24 is directly connected, Loopback0 S* 0.0.0.0/0 [1/0] via 192.168.10.3 |
- R1 ARP 캐시 정보
| Protocol Address Age(min) Hardware Addr Type Interface Internet 192.168.10.2 1 cc01.0400.0000 ARPA FastEthernet0/0 Internet 192.168.10.3 81 cc02.0400.0000 ARPA FastEthernet0/0 Internet 192.168.10.1 - cc00.0400.0000 ARPA FastEthernet0/0 |
이는 R2의 Fa0/0 인터페이스가 비활성화되면, R1은 패킷을 R3로 전달하게 된다. 이를 위해 R1의 라우팅 테이블에서 R2의 경로는 더 이상 유효하지 않으며, 대신 10.10.10.0 네트워크로 향하는 경로가 R3를 통해 전달된다. R1은 R3와의 연결을 유지하고, ARP 캐시에는 R3의 MAC 주소가 저장되어 해당 목적지로 패킷을 전달할 수 있다.
R1에서 ARP 캐시 정보에는 192.168.10.2 (다음 홉의 IP 주소)의 정보가 활성화되어 있지만, 라우팅 테이블에는 해당 경로가 사라진 상태이다. 이로 인해 통신의 절단이 약 1초 정도 발생하고, 이후 모든 트래픽은 R3를 통해 전송된다. 이 상태에서 IP SLA 모니터와 관련된 트래킹 정보는 다음과 같다.
- R1 트래킹 정보
| R1 # show track 10 Track 10 Response Time Reporter 1 reachability Reachability is Down 37 changes, last change 00:00:01 Latest operation return code: Timeout Tracked by: STATIC-IP-ROUTING 0 R1 # show track 20 Track 20 Response Time Reporter 2 reachability Reachability is Up 15 changes, last change 00:15:57 Latest operation return code: OK Latest RTT (millisecs) 80 Tracked by: STATIC-IP-ROUTING 0 |
위와 같은 이더넷 기반의 환경에서 정적 라우팅을 사용하는 경우, 연결된 회선이 직접 연결되지 않고 스위치 장비 등을 통해 연결된 원격지 회선이 절단되었을 때, LLCF(Loopback Connection Failure Detection)가 지원되지 않는다면 항상 문제가 발생할 수 있다. 이러한 문제의 근본적인 원인은 ARP 테이블의 갱신 주기가 Cisco 라우터나 백본 스위치에서 기본값으로 4시간에 설정되어 있기 때문이다. 이로 인해 연결 상태가 빠르게 변하는 환경에서 ARP 캐시가 갱신되지 않으면, 장애 발생 시 패킷이 잘못된 경로로 전달될 수 있다.
따라서 이 문제를 극복하기 위해 ARP 캐시 테이블의 갱신 주기를 1초로 극단적으로 줄이는 방법도 하나의 해결책이 될 수 있다. 이를 통해 네트워크의 연결 상태가 변경될 때마다 ARP 캐시가 신속하게 갱신되어 장애 발생 시 빠르게 대응할 수 있으며, 네트워크 안정성을 높이는 데 도움이 될 것이다.
- R1의 ARP 캐시 정보 갱신 주기 변경
| R1 # show interface fa0/0 FastEthernet0/0 is up, line protocol is up Hardware is AmdFE, address is cc00.0400.0000 (bia cc00.0400.0000) Internet address in 192.168.10.1/24 MTU 1500 bytes, BW 100000 Kbit, DLY 100 usec, reliability 255/255, txload 1/255, rxload 1/255 Encapsulation ARPA, loopback not set Keepalive set (10 sec) Full-duplex, 100Mb/s, 100BaseTX/FX ARP type: ARPA, ARP Timeout 04:00:00 # 변경 이전 값 Last input 00:00:00, output 00:00:00, output hang never ...(생략) R1(config-if) # arp timeout 1 R1(config-if) # end R1 # show interface fa0/0 FastEthernet0/0 is up, line protocol is up Hardware is AmdFE, address is cc00.0400.0000 (bia cc00.0400.0000) Internet address is 192.168.10.1/24 MTU 1500 bytes, BW 100000 Kbit, DLY 100 usec, reliability 255/255, txload 1/255, rxload 1/255 Encapsulation ARPA, loopback not set Keepalive set (10 sec) Full-duplex, 100Mb/s, 100BaseTX/FX ARP type: ARPA, ARP Timeout 00:00:01 # 1초로 변경 Last input 00:00:00, output 00:00:00, output hang never ...(생략) |
ARP 갱신 주기를 조정한 후, 동일하게 R2의 인터페이스를 비활성화하여 R1에서 라우팅 테이블을 확인하면, 최대 1초의 에이징 타임(Aging time) 후에 R2로의 라우팅 정보가 삭제되는 것을 확인할 수 있다.
라우팅 구간에서의 ARP 정보는 호스트가 연결되는 구간에 비해 브로드캐스트 영향 범위가 상대적으로 작기 때문에, ARP 갱신 주기를 1초로 변경하더라도 큰 문제가 되지 않을 것이다.
결과적으로, Cisco 장비의 트래킹 기법은 WAN 라우팅 구간에서 정적 라우팅을 통해 연결되는 경우와, ARP 캐시 갱신 주기 조정이 필요한 경우에 적용된다. 특히, 이더넷 라우팅 구간에서 LLCF(Loopback Connection Failure Detection)가 동작하지 않는 장비를 경유해 정적 라우팅을 설정할 때 이 방법을 활용할 수 있다. 다만, 이 두 가지 방법 모두 서비스 중단 시간이 최대 1초까지 발생할 수 있음을 감수해야 한다.
(2) Cisco 장비의 PBR을 이용한 다중 트래킹
Cisco 장비에서는 PBR(Policy-Based Routing)을 사용하고 다중 트래킹(Multiple Tracking) 옵션을 설정하여 LLCF(Loopback Connection Failure Detection) 기능을 대신 해결할 수 있다. 이 기능은 Cisco IOS Enterprise Version 12.3(4)T 이상에서 지원되며, 트래킹에 사용할 수 있는 트래픽 유형은 ICMP, UDP Ping, HTTP GET 요청 등이 있다. 이를 통해 네트워크 경로의 상태를 실시간으로 모니터링하고, 경로 변경 시 신속하게 트래픽을 재조정할 수 있다.
- 다중 트래킹 설정 단계
| Router(config) # rtr 11 # 글로벌 모드에서 SSA 동작 설정과 SAA RTR 설정 모드 진입 Router(config) # type echo protocol ipicmpecho 192.168.6.1 # 동작 감시를 위한 SAA 종단 간 응답 시간 설정 Router(config) # rtr schedule 11 life forever start-time now # SAA 동작을 위한 시간 파라미터 설정 Router(config) # track 100 rtr 11 reachability # RTR 개체 중 도달성에 대해 트랙하고 트래킹 설정 모드로 진입 Router(config) # delay up 60 down 30 # (옵션) 트래킹 할 개체의 통신 상태 변화에 대한 지연 시간 주기 설정 Router(config) # interface gi2/1 Router(config-if) # ip policy route-map tracking # 인터페이스에 라우트 맵을 통한 정책 적용 Router(config) # route-map tracking Router(config-route-map) # set ip next-hop verify-availability 192.168.6.1 10 track 100 # 유효성을 트랙할 다음 홉을 설정 [ip-address sequence track object] # SAA : Service Assurance Agent, RTR : Response Time Reporter |
- 다중 트래킹 설정 예
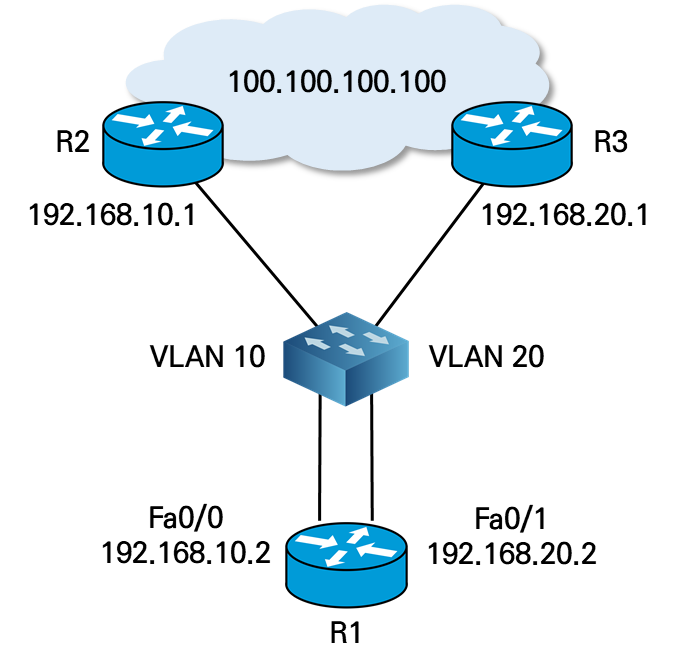
- 100.100.100.100에 대한 정적 라우팅 트래킹 설정
| R1(config) # track 10 rtr 5 reachability R1(config-track) # exit R1(config) # rtr 5 R1(config-rtr) # type echo protocol ipicmpEcho 192.168.10.1 R1(config-rtr-echo) # exit R1(config) # rtr schedule 5 life forever start-time now R1(config) # ip route 100.100.100.100 255.255.255.255 192.168.10.1 track 10 R1(config) # ip route 100.100.100.100 255.255.255.255 192.168.20.1 |
- R1의 라우팅 테이블에서 R2의 다음 홉 설정 확인
| R1 # show ip route ...(생략) Gateway of last resort is not set 200.200.200.0/32 is subnetted, 1 subnets C 200.200.200.200 is directly connected, Loopback 0 100.0.0.0/32 is subnetted, 1 subents S 100.100.100.100 [1/0] via 192.168.10.1 C 192.168.10.0/24 is directly connected, FastEthernet0/0 C 192.168.100.0/24 is directly connected, Loopback0 |
- R2 인터페이스 다운 시, 정상 상태에서 Reachability is down 상태 변경
| R2(config-if) # shut R2 # show track Track 10 Response Time Reporter 1 reachability Reachability is Up 3 changes, last change 00:03:54 Latest operation return code: OK Latest RTT (millisecs) 1480 Tracked by: STATIC-IP-ROUTING 0 R2 # show track Track 10 Response Time Reporter 2 reachability Reachability is Down 4 changes, last change 00:00:00 Latest operation return code: Timeout Tracked by: STATIC-IP-ROUTING 0 |
- 라우팅 테이블에서 트래킹 상태 정보에 따른 변경 내용 확인
| R1 # show ip route ...(생략) Gateway of last resort is not set 200.200.200.0/32 is subnetted, 1 subnets C 200.200.200.200 is directly connected, Loopback 0 100.0.0.0/32 is subnetted, 1 subents S 100.100.100.100 [1/0] via 192.168.20.1 C 192.168.10.0/24 is directly connected, FastEthernet0/0 C 192.168.100.0/24 is directly connected, Loopback0 |
'네트워크 > 물리계층과 데이터 링크계층' 카테고리의 다른 글
| [물리 계층과 데이터 링크 계층] BFD(Bi-directional Forwarding Detection) (1) | 2024.12.03 |
|---|---|
| [물리 계층과 데이터 링크 계층] LACP 및 PAgP 구성 (0) | 2024.12.02 |
| [물리 계층과 데이터 링크 계층] PAgP(Port Aggregation Protocol) (0) | 2024.12.02 |
| [물리 계층과 데이터 링크 계층] LACP(Link Aggregation Control Protocol) (1) | 2024.12.02 |
| [물리 계층과 데이터 링크 계층] VLAN(Virtual Local Area Network) (3) | 2024.11.12 |


